
I’ve spent a lot of time in the past couple of months thinking about the role of the software developer in the future. There was (and still is!) a lot of gloom and doom on the future of the craft. One thing that is obvious is, that the role of the developer will shift dramatically from “the guy writing the code” to “the guy doing orchestration”, to the point where we don’t even look at code anymore. I’m aware that that last bit is something people will argue about (… a lot, from my experience). However, let’s assume for a moment, that this is correct, what would the right tooling look like? It for sure would not be an editor like VS Code or a fullblown IDE like Eclipse, since those are tools that are tuned towards working with code – the very same thing we assume we won’t do anymore in the future, meaning those are likely not the kind of tools we need.
So, over the Easter weekend I sat down to think about this and did some prototyping.
What problems do we want to solve?
Before we dive into the results, we first have to set our objective. For me, I went into this thinking about the specific things that should be simpler when doing AI driven development and tried to build something around that:
- Context: As with a regular developer, one of the most important bit we need to provide to an agent is the right context. Agents are quite good at figuring out code, but this will take a lot of tokens and also what they build for themselves usually does not contain past exchanges a user had with the agent, nor does it contain relationships that themselves provide a meaning.
- History: While it is possible to instruct the agent to somehow protocol everything for you, a lot of the small exchanges often get lost. Also agents will usually neither persist plans they make for future reference nor their implementation summaries (which themselves are valuable inputs for future work!). All this can be overcome, but the current breed of CLI tools does a poor job of that.
- Structure: Agents often struggle not to break things, because relations between features are in many instances not as explicit as they could be.
- Finding contradictions: Agents will happily implement what they are told. Since they usually don’t remember past prompts nor requirements they will not be able to tell if the user accidentally created conflicting prompts.
- Inherent parallelism: In my experience development using agents is an inherently parallel endeavor. While the agent is working to implement the user is busy either testing or specifying the next feature. This means it must be possible for the user to recover a previous chain of discussion with the AI easily. Current tools make this hard.
So, thinking about this and about how tools like Jira and Polarion work made me realize, that the obvious first attempt at a solution would be a knowledge graph, where each feature is a node and each edge is a relationship between nodes. Node content then is simply the data that was generated in the context of implementing a work-item, that is:
- The initial prompt
- The plan
- Implementation notes
- Any interaction between the agent and the user that happened while developing the feature.
An agent, that is tasked with implementing a related feature can walk the graph to see how the original feature was implemented, what prompt went into, what was implemented, maybe which git commits make up the feature. All this will ensure, that the agent will get very focused information and can automatically build the correct context itself.
Synapse – an agentic development environment
I used the weekend to prototype an application called “Synapse”. This is essentially a software development environment that has a knowledge graph at its core and is driven by different AI agents. The user writes specs, agents write plans for the specs, the user approves plans and implementations – our well known flow. However, Synapse brings the knowledge graph, that allows the agent to see the intention behind already implemented features months after the fact, even if the user that picks up a feature again is not the one who originally specified it.
In Synapse features are usually linked up with related features and agents will typically traverse the knowledge graph to find the data they need:
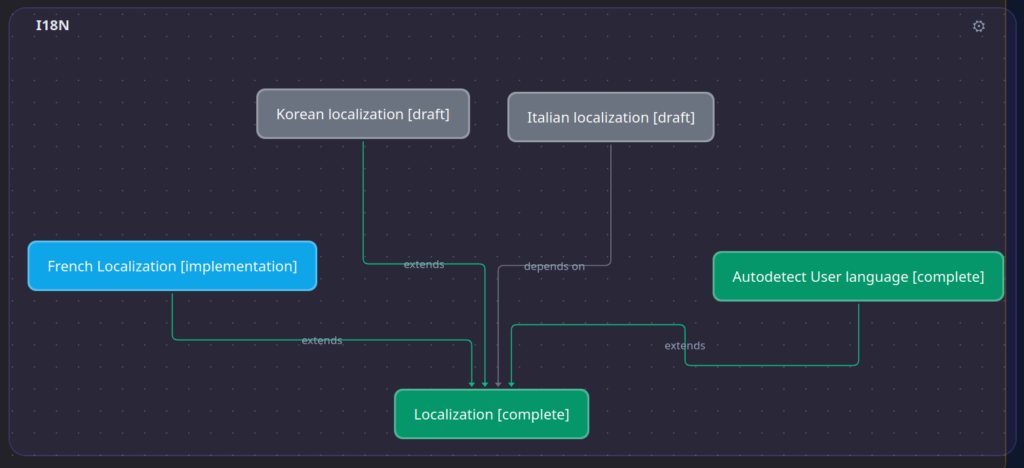
The user starts by typing out a rough description of the feature they want to implement. They can link the feature up to related features. Once they are happy with their work, they hand it over to the AI by promoting it to the planning phase. An AI agent will pick up the description, the surrounding/related work items and create a plan for implementation given that input. It might get to a point where ambiguities need to be resolved or where the user has to make a decision. In these cases the items are flagged and handed back to the user:
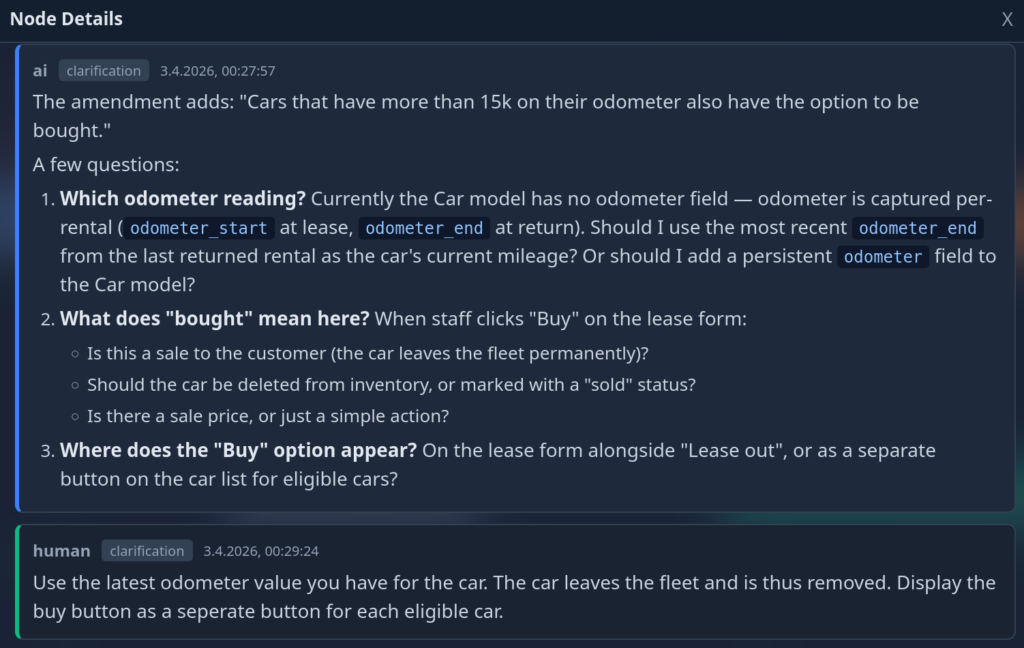
These interactions are recorded for future reference. Once all questions of the AI are satisfied, the final plan is created and again presented to the user:
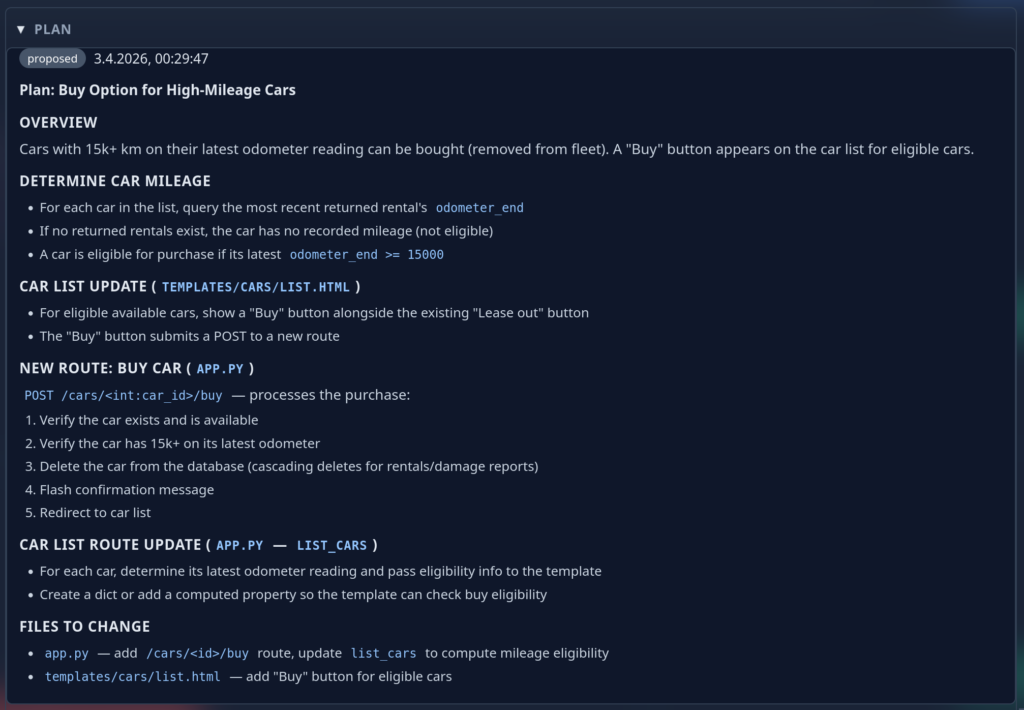
Again the user has the option to intervene and have the AI change the plan. Once the user is happy they green-light implementation and the AI starts working in the background. As soon as the implementation is finished the ticket is handed back to the user again for review, this time containing implementation notes (and obviously the code):
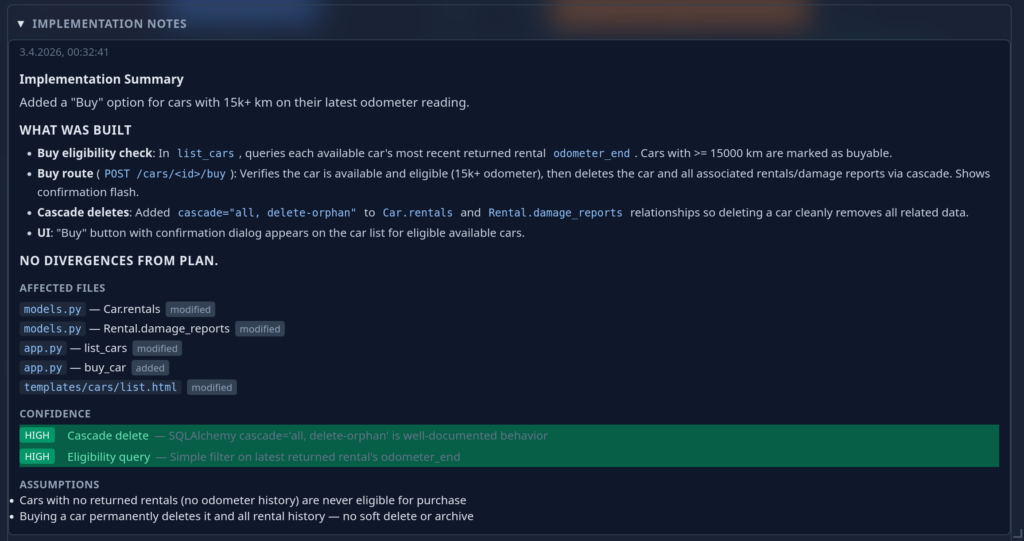
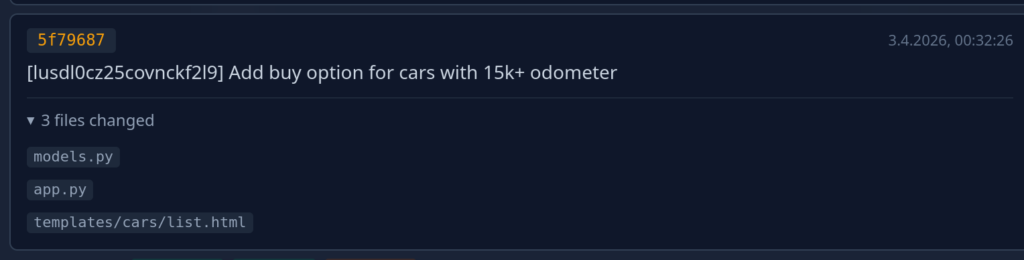
Again: Once the user is happy with the implementation they accept it and the ticket changes state to “implemented”. Now, the neat thing is that all this data stays available and an agent that works to extend this feature or works on related features is able to access it during planing. Even more interesting: If we change the specification of this feature later on, the AI can gauge the impact of the change across the project:
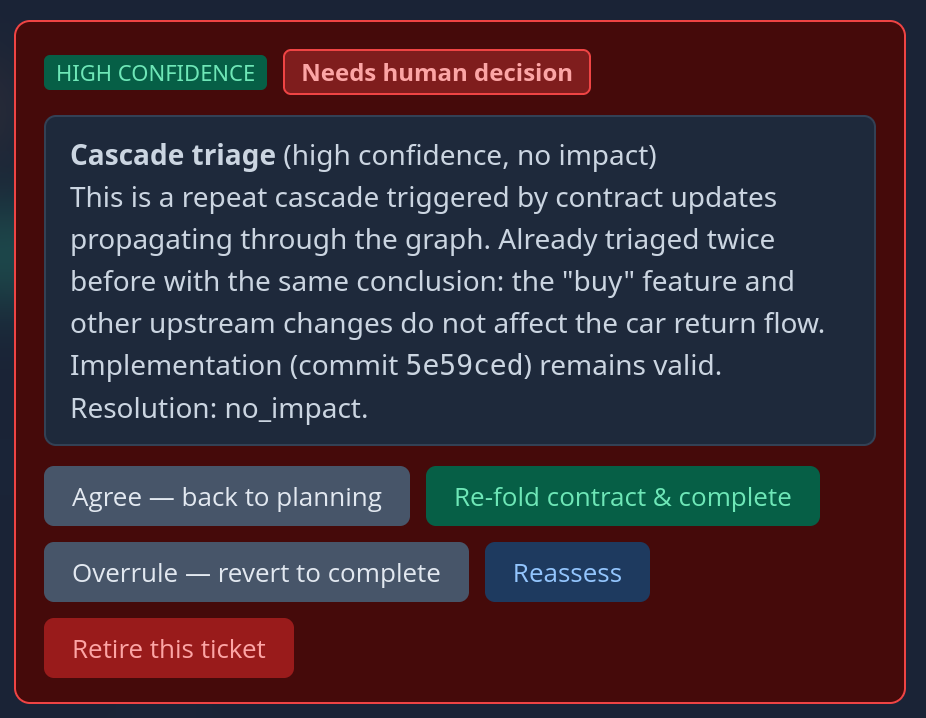
Also: Since the agent can walk the graph changes can be propagated through the whole graph and we see where they hit.
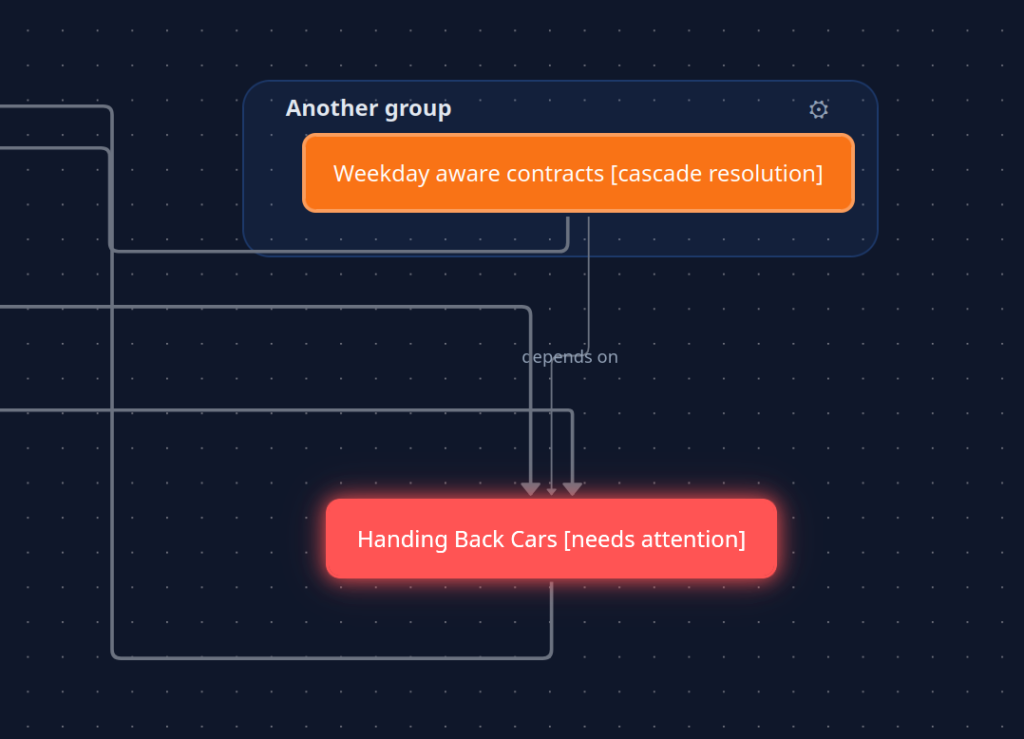
So, what did I learn?
Given the time I invested in thinking this up and implementing it it actually works phenomenally well. The automatic context acquisition is a powerful tool that limits regressions. Automatic analysis of tickets for consistency is super powerful.
However…
While I do think the idea of the knowledge graph is fundamentally correct for the problem that needs solving, it immediately poses the problem of managing data for the user, so they can actually work with it. A simple project already looks like this:
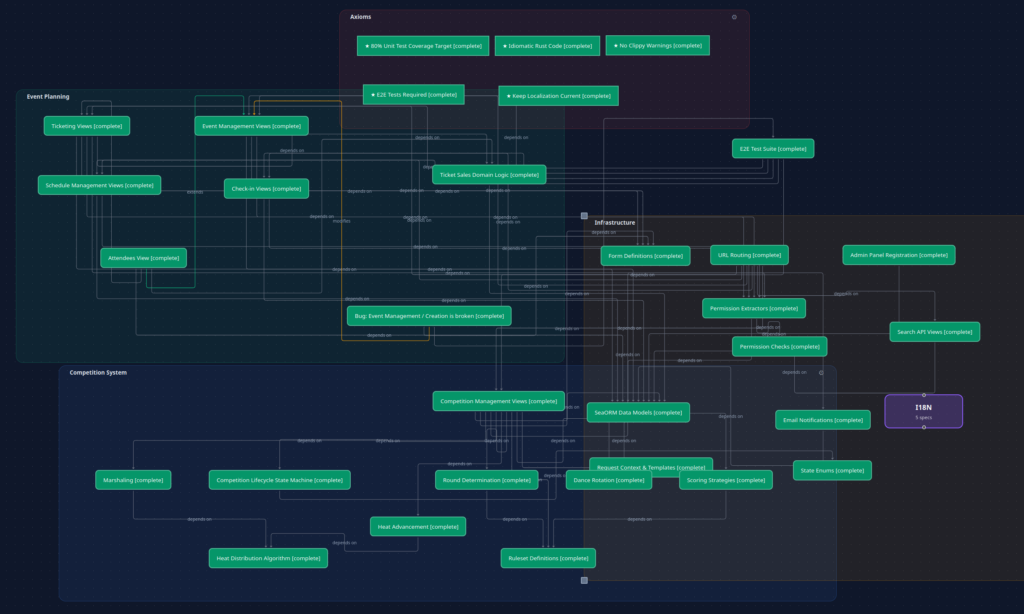
As we can see – already a bloody mess of relationships (albeit correct and useful relationships). Making the individual groups of items collapsible helps:

But I’m not sure if this is really the optimal solution to present data to the user.
TL;DR:
“Synapse” is an experimental software development environment for AI first software development. It tries to tackle the challenges AI assisted software development poses for developers.
Foto von Daniil Komov auf Unsplash